1 实验目的
了解Kafka、HDFS、MapReduce在Hadoop体系结构中的角色,并通过本次综合实验对大数据技术在实际应用中的主要流程有初步的认识;
2 实验环境
实验平台:基于实验一搭建的虚拟机Hadoop大数据实验平台上的Kafka、HDFS、MapReduce集群;
编程语言:JAVA(推荐使用)、Python、C++等;
3 实验内容
- 编程实现Kafka生产者,模拟数据采集的过程,向指定topic发送数据。
- 编写MapReduce程序,消费上述topic中的数据,并对数据进行一定的处理,如求和、排序等。(可选用Spark代替MapReduce)
- MapReduce程序将处理结果存储到HDFS文件系统中。(可选用Hbase或Hive代替HDFS,需要分别设计Hbase表和Hive表)
- 对以上实验内容编写实验报告,并提交实验相关代码。
4 实验内容
本次实验使用数据集同Kafka数据采集实验中的数据集。
5 准备工作
// 重启时间同步服务(cluster1 上)
service ntpd restart
// 同步时间(cluster2 和 cluster3)
ntpdate cluster1
// 切换到用户hadoop(三台)
su hadoop
//启动zookeeper(三台)
zkServer.sh start
//启动kafka(三台)
kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties &
// 启动 HDFS(cluster1 上)
start-dfs.sh
// 启动 YARN(cluster1 上)
start-yarn.sh
6 Kafka生产者发送数据
编程实现Kafka生产者,模拟数据采集的过程,向指定topic发送数据。
编写代码ghbProducer.java
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
import java.util.Scanner;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class ghbProducer {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "cluster1:9092");
Producer<Integer, String> producer = new Producer<Integer, String>(new ProducerConfig(props));
String topic;
System.out.print("请输入topic名称:");
topic = in.next();
File file = new File("kafka采集数据实验.txt");
BufferedReader reader = null;
System.out.print("请输入发送数据行数:");
int num = in.nextInt();
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
while ((tempString = reader.readLine()) != null) {
producer.send(new KeyedMessage<Integer, String>(topic, tempString));
System.out.println("成功发送第 " + line + " 行数据...");
if (line == num)
break;
line++;
}
reader.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
producer.close();
}
}
打开WinSCP,将ghbProducer.java和实验数据上传至虚拟机cluster1的/home/hadoop路径下。
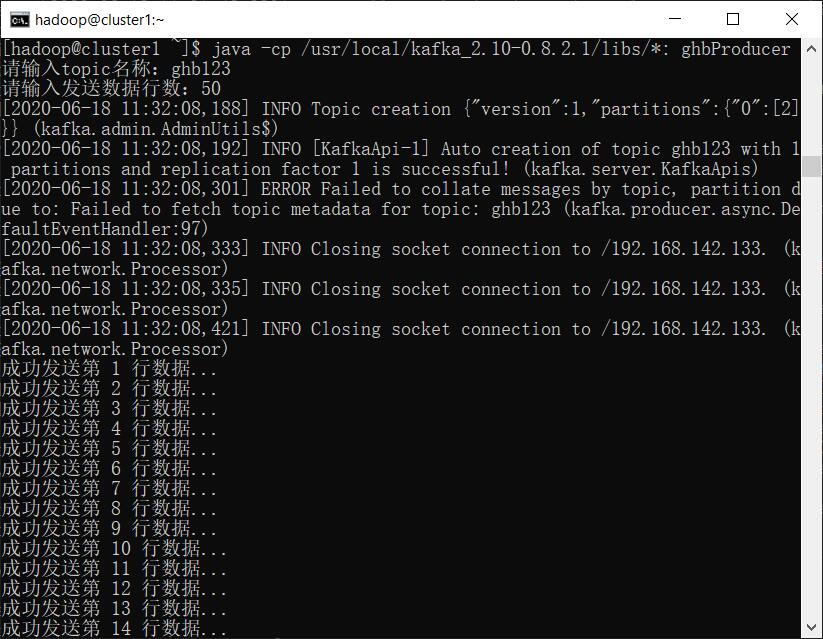
在cluster1上执行
cd /home/hadoop
// 编译
javac -cp /usr/local/kafka_2.10-0.8.2.1/libs/*: ghbProducer.java
// 运行
java -cp /usr/local/kafka_2.10-0.8.2.1/libs/*: ghbProducer
7 消费并处理数据,存储到HDFS文件系统中
主要思路:先从Kafka获取数据,保存到目录ghb_lab5_input中;然后使用MapReduce对数据进行排序,输出到目录ghb_lab5_output;最后将处理后的数据上传到HDFS的根目录下,文件名为lab5out.txt。
编写代码ghbMapReduce.java
import java.util.*;
import java.io.*;
import java.net.*;
import kafka.consumer.*;
import kafka.javaapi.consumer.ConsumerConnector;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.fs.FileSystem;
public class ghbMapReduce {
final static String INPUT_PATH = "ghb_lab5_input";// 输入目录
final static String OUTPUT_PATH = "ghb_lab5_output";// 输出目录
public static void main(String[] args) {
// 消费数据
Consume();
// 排序
Sort();
// 保存到HDFS
SaveToHDFS();
}
private static void SaveToHDFS() {
try {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://cluster1:9000");
FileSystem fs = FileSystem.get(uri, conf);
// 本地文件
Path src = new Path(OUTPUT_PATH + "/part-r-00000");
// HDFS存放位置
Path dst = new Path("/lab5out.txt");
fs.copyFromLocalFile(src, dst);
System.out.println("Upload to " + conf.get("fs.defaultFS"));
} catch (Exception e) {
e.printStackTrace();
}
}
private static void Sort() {
try {
Runtime.getRuntime().exec("rm -rf " + OUTPUT_PATH);// 删除上次的输出目录
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "ghbMapReduce");
job.setJarByClass(ghbMapReduce.class);
// job.setJar("sortTest.jar");
job.setMapperClass(sortMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(sortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
job.waitForCompletion(true);
// System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class sortMapper extends Mapper<Object, Text, Text, Text> {
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 框架默认是根据键key进行排序,所以先把数字转移到key上面
context.write(value, new Text(""));
}
}
public static class sortReducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 在key前面在加上一个表示位置的序号
// context.write(new Text(index + " " + key.toString()), new Text(""));
context.write(key, new Text(""));
}
}
private static void Consume() {
try {
Scanner in = new Scanner(System.in);
String topic, path;
System.out.print("请输入topic名称:");
topic = in.next();
System.out.print("请输入消费数量:");
int num = in.nextInt();
System.out.print("保存至文件:");
path = in.next();
path = INPUT_PATH + "/" + path;
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
int i = 1;
BufferedWriter bw = new BufferedWriter(new FileWriter(path));
while (i <= num) {
String out = new String(it.next().message());
bw.write(out + '\n');
System.out.println("消费第" + i + "行数据 " + out);
i++;
}
bw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("group.id", "group1");
props.put("zookeeper.connect", "cluster1:2181,cluster2:2181,cluster3:2181");
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
}
打开WinSCP,将ghbMapReduce.java上传至虚拟机cluster2的/home/hadoop路径下。
cluster2上执行
cd /home/hadoop
// 创建文件夹
mkdir ghb_lab5_input
// 构造新的命令ghb_javac,注意下面是一行,不要写成多行
alias ghb_javac="javac -cp /usr/local/hadoop-2.6.5/share/hadoop/common/*:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/*:/usr/local/kafka_2.10-0.8.2.1/libs/*:"
// 构造新的命令ghb_java,注意下面是一行,不要写成多行
alias ghb_java="java -cp /usr/local/hadoop-2.6.5/share/hadoop/common/*:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/*:/usr/local/kafka_2.10-0.8.2.1/libs/*:"
// 编译
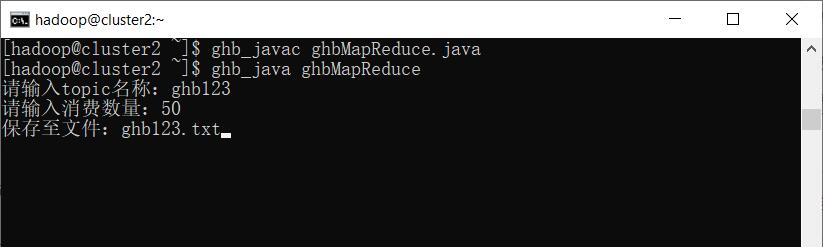
ghb_javac ghbMapReduce.java
// 运行
ghb_java ghbMapReduce
输入topic名称、消费数量、保存文件名等信息。
8 查看运行结果
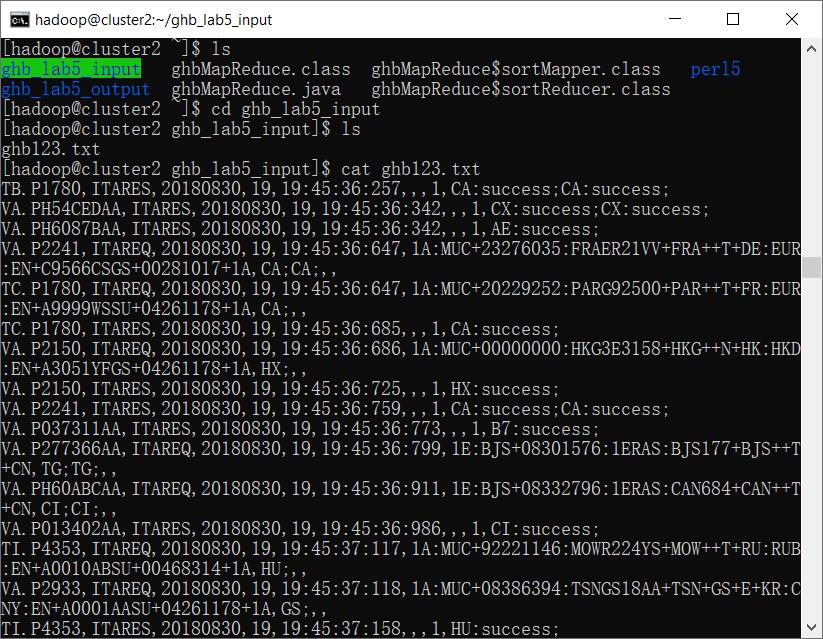
8.1 查看从Kafka读取的数据
cluster2上执行
cd ghb_lab5_input
ls
cat ghb123.txt
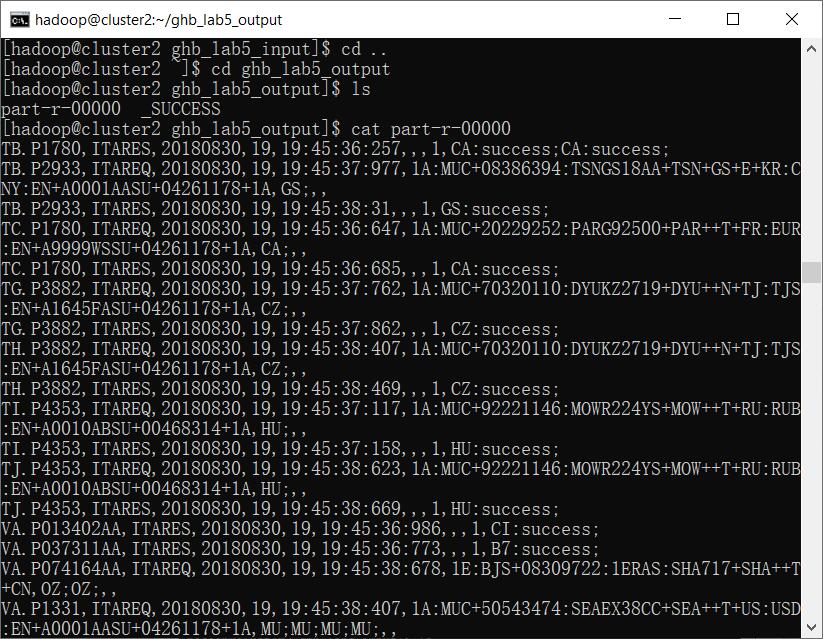
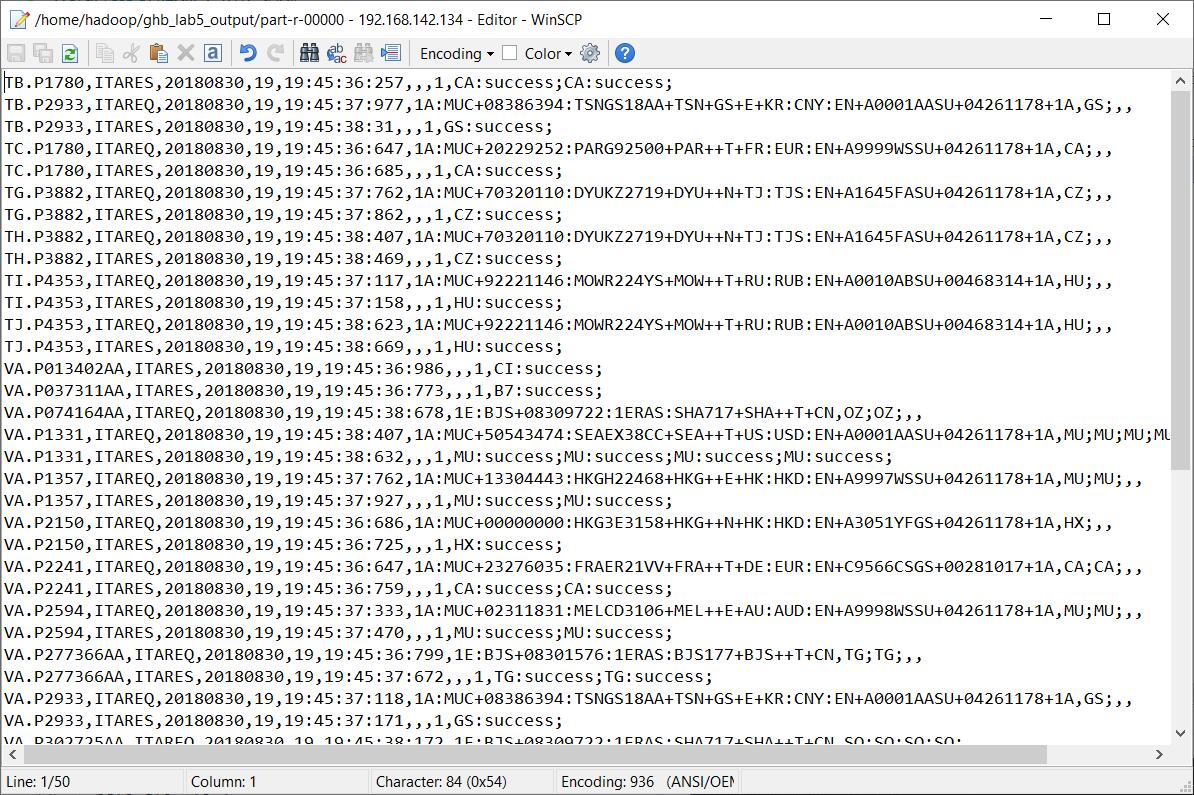
8.2 查看排序处理后的数据
cluster2上执行
cd ..
cd ghb_lab5_output
ls
cat part-r-00000
8.3 查看上传到 HDFS 的文件
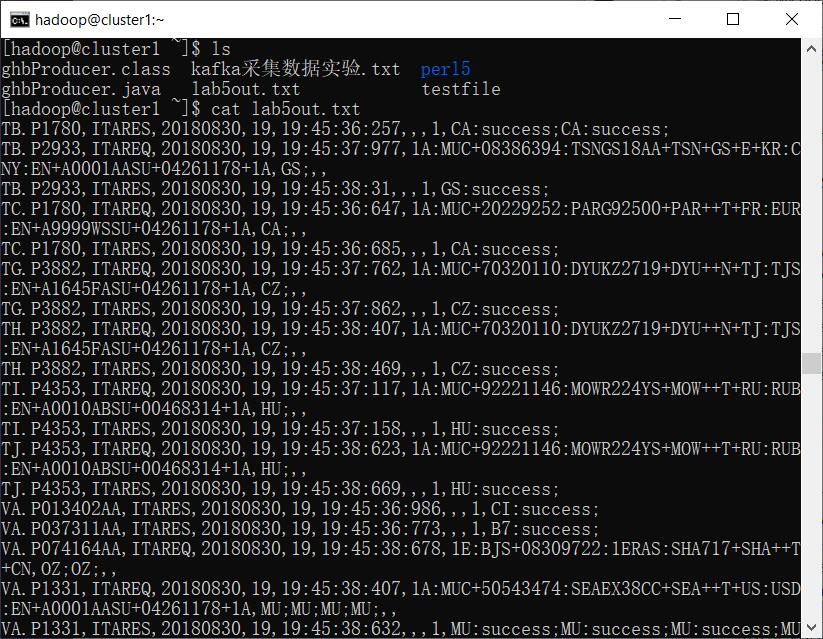
cluster1 或 cluster3上执行
// 查看hdfs根目录
hdfs dfs -ls /
// 将lab5out.txt下载到本地
hdfs dfs -get /lab5out.txt
ls
cat lab5out.txt
9 关机前操作
//停止kafka(三台)
kafka-server-stop.sh
//停止zookeeper(三台)
zkServer.sh stop
// 关闭 HDFS(cluster1 上)
stop-dfs.sh
// 关闭 YARN(cluster1 上)
stop-yarn.sh
哥,这程序得运行多长时间啊,我这咋半小时都不出结果。。。还是有什么冲突跑不不出来啊